
Elasticsearch原理浅析
简介
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
应用场景
维基百科和百度百科,手机维基百科,全文检索,高亮,搜索推荐。
The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
GitHub(开源代码管理),搜索上千亿行代码。
电商网站,检索商品。
日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅手机的监控,如果iphone的手机低于3000块钱,就通知我,我就去买
BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化国内。
国内:站内搜索(电商,招聘,门户,等等),IT OA系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
es名词介绍
- index:相当于数据库的表
- document:相当于数据库的每一行数据
- field: 相当于数据库中的字段
- shard: 分区,一个index会分为多个shard,一个primary shard和多个replica shard
- primary shard: 主分区负责读写
- replica shard:副本,只读,主分区故障副本,投票数大于n/2+1
- refresh:数据从缓存刷新到translog
- flush:translog刷到硬盘
- fsync:持久化到磁盘需要fsync操作,translog持久化,flush都会用到
- 倒排索引:对文档字切分成很多关键字,通过关键字定位到document
原理浅析
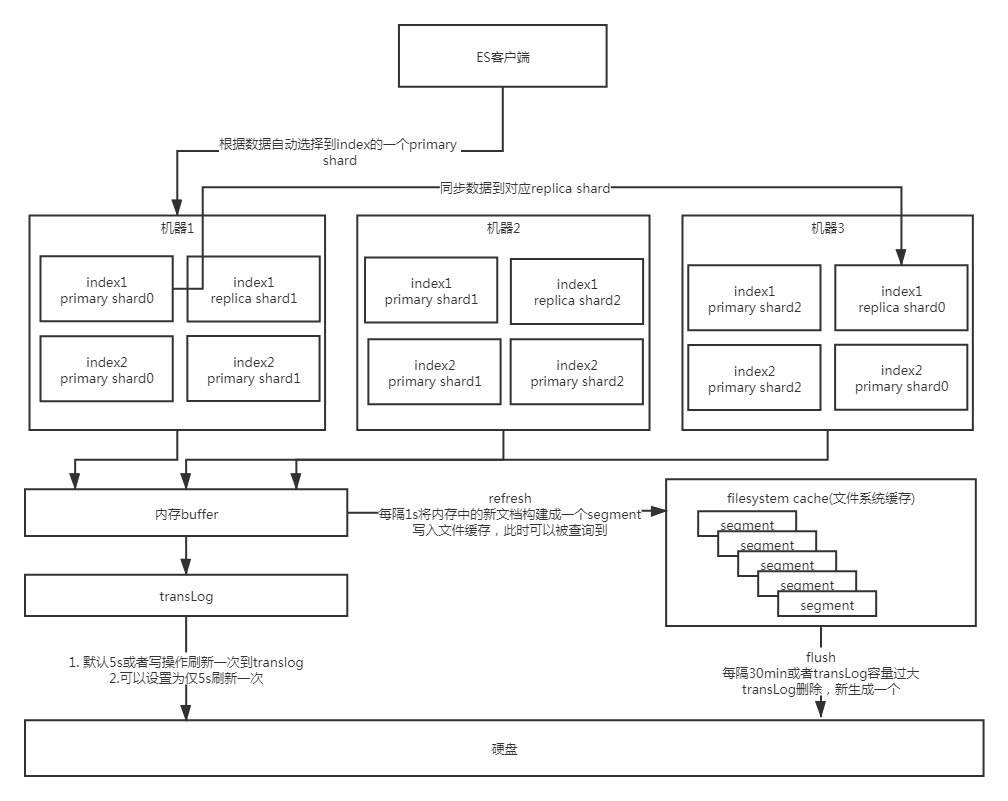
ES客户端请求时默认会根据文档id hash取模请求到对应的primary shard
primary shard会同步数据到对应的replica shard
primary shard和replica shard都会将数据放入内存buffer中,并追加到transLog
默认情况每过5s或者每次写操作都会将transLog通过fsync到硬盘上,此时会稍微影响写性能,如果丢失数据无影响,可以设置为仅5s刷新一次
内存buffer中的数据是不可读的,每隔1s会refresh内存buffer数据到一个新建的segment中,此时数据可读
当translog容量过大或者30min后会生成新的transLog,将文件缓存系统中的segment全部持久化到硬盘中并删除transLog
SpringBoot集成ES
新建SrpingBoot项目添加依赖:
1 | <dependency> |
安装好ES增加如下配置:
1 | # Elasticsearch |
新建Controller测试增删改查:
1 | import com.alibaba.fastjson.JSONObject; |

